Get Clues from URLs
http://useful.clue.net/
| Use the URL as a clue - it can provide a lot of information about a resource and your location within it. |
URLs:
- specify the name and address of a resource on the Internet
- are hierarchical, reading from left to right
- tell you about the way you access the resource, the computer you access it from and the name of the file you access
- give human-readable names to the (hidden) numeric addresses understood by machines (Internet Protocol (IP) numbers)
- make use of the global Domain Name System (DNS) which translates between the human-readable Internet address and the numeric, machine-readable address allowing different machines to communicate on the network
- can provide information about the organisation (or individual) providing the resource
- often contain the geographical location of the server
http://www.bps.org.uk/publicat/Periodicals/Psych/PSY9_97.HTM

So just by looking at this URL you can deduce that:
- it will take you to a WWW page
- it will take you to a server (machine holding the Web site) called "www.bps"
- that this server has been registered as belonging to an "organisation"
- that the server has been registered in the United kingdom
- the URL will take you to a file that someone has called "PSY9_97"
- "PSY9_97" has been filed in a directory called "Psych"
- the "Psych" directory has been filed within another directory, called "Periodicals"
- "Periodicals" has been filed within a directory called "publicat"
- You will find a UK Web site belonging to an organisation.
- You will find a file, within a directory, within a directory, within a directory ie. you'll be taken to a page deep within a collection of related resources.
Dissecting URLs
The basic structure of a URL is:protocol://server-name.domain-name/directory/filename
1) Protocol
The first part of a URL - before the colon - describes the access method.Data can be made available on the Internet via a number of different
protocols:
| http:// | a World Wide Web server (WWW) |
| ftp:// | File Transfer Protocol |
| mailto: | |
| telnet:// | Telnet |
| gopher:// | gopher |
2) Server name
The second part of a URL - after the // and before the next full stop - tells you about the machine (called a server) that you are accessing.For example:
http://sosig.ac.uk/
.... indicates that the machine that holds the information is called "sosig".3) Domain name
After the server name you will see the domain name. This can tell you the country in which the server is based and the nature of the organisation that owns the server.For example:
.ac.uk
... indicates that the resource is held on an academic server (.ac) in the United Kingdom (.uk).Country identifiers
You can get a clue about the country the server is based in from the country identifier. For example:| au | Australia |
| ca | Canada |
| de | Germany |
| fr | France |
| uk | United kingdom |
The exception to this is the USA which does not use its country code (.us).
Organisation identifiers
You can get clues about the nature of the organisation that owns the server from the organisation identifier. For example:| ac, edu | academic or educational servers |
| co, com | commercial servers |
| gov | government servers |
| org | non-governmental, non-profit making organisations |
Note that the USA uses different organisation identifiers from those used in Europe.
A list of country and organisation identifiers
is available.
Warning!The domain and server names may not always be straightforward clues about the location and source of the information.People can call their servers any name they wish and it is possible for them to register them with domain names that give false impressions. For example, it is possible (though perhaps unlikely) that the URL: http://MacDonalds.comdoes not point to the site of a hamburger outlet but to "Old MacDonald's Farm Supplies" ! |
4) Directories and filenames
After the domain names, between the next set of slashes (/) you will see the names of directories containing the file you are accessing.Many Internet resources are organised into directory structures similar to those found in other computer applications. These can provide useful clues about the structure of the site.
For example:
http://www.bps.org.uk/publicat/Periodicals/Psych/PSY9_97.HTM
has a fairly complex directory structure - three directories are given (publicat, Periodicals and Psych) before you see the name of the actual file (always at the end on the right hand side of the URL).This is a clue as to the size and complexity of the site - generally speaking, the more directories, the more complex the site.
This is also a clue that this URL would take you to a file deep within the site.
Being speculative, this URL probably takes you to a 1997 issue of a
periodical on a subject from the field of psychology.
Practical Hints and Tips
Deleting parts of the URL to learn more about the site
It can be very useful to delete part of the right hand side of the URL to see where the new, shorter URL takes you.By doing this you can get clues as to your location within the site and the structure of the site.
By deleting URLs from the right hand side to the slash marks (/) you will move up the directory tree and see how the file is embedded in the site.
For example, look what happens if you delete part of the following URL:
| URL | Points to: | tells you: |
| http://www.ariadne.ac.uk/issue13/music/ | an online article | this is an online article |
| http://www.ariadne.ac.uk/issue13/ | the contents page of issue 13 of a journal | the article is in issue 13 of this journal |
| http://www.ariadne.ac.uk/ | the home page of an e-journal | the article is contained in this journal |
You can delete part of the URL by putting your cursor at the end of the URL in the "location box" and pressing the "back" or "delete" key until you reach the slash (/), then press the "Return" key.
Delete from the right, up to the slashes in the URL.
This technique can be especially useful for long URLs.
The tilde ~ sign
In some URLs you will see the tilde sign which looks like this: ~For Example:
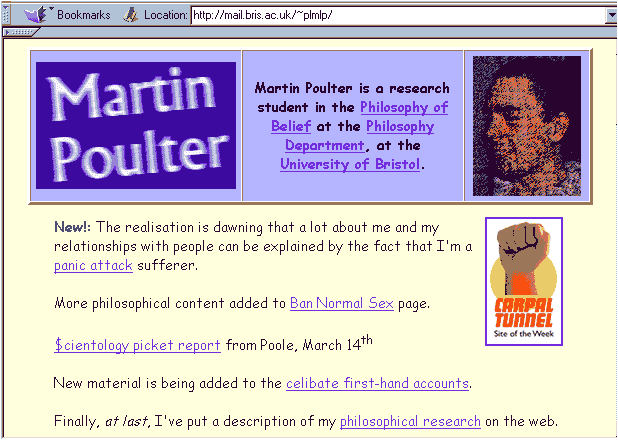
http://mail.bris.ac.uk/~plmlp/
Use the tilde as a clue!Most BR>servers use the ~ symbol to represent the personal directories of individuals.
If the URL contains a tilde then be aware that you are probably (although not definitely) looking at a personal page with personal opinions rather than an official site giving the official line.
However, this does not mean that the information is necessarily of poor quality
For example the following Web page has a tilde in the URL. The
page is located on a University of Bristol server, but is NOT an official
page of the University - it is the personal page of a member of staff.
PURLs
Some URLs will have the word "PURL" located in the early part of the URL.PURL stands for Persistent Uniform Resource Locator. For example:
http://purl.org/metadata/dublin_core
A PURL is a clue that the owner of the resource is committed to keeping the site stable and persistently available via a given URL.To obtain a PURL the owner has had to register the site with an intermediary PURL service. If for any reason the site moves addresses the owner registers the change of address with the PURL service which then redirects any users to the new URL.
A PURL address should not lead you to a dead link and should mean that the same URL will always point to the same resource even if, behind the scenes, the resource has been moved from server to server.